#1. TCP 커넥션
모든 HTTP 통신은 패킷 교환 네트워크 프로토콜들의 계층화된 집합인 TCP/IP를 통해 이루어진다.

- (1)~(3)에서 URL을 통해 서버의 IP주소와 포트 번호를 가져온다.
- (4)에서 웹 서버가 TCP커넥션을 맺고 (5)에서 그 커넥션을 통해 요청 메시지가 전달된다.
- (6)에서 응답을 읽고 (7)에서 커넥션이 끊어진다.
TCP 스트림은 세그먼트로 나뉘어 IP 패킷을 통해 전송된다.

- HTTP는 'IP, TCP, HTTP'로 구성된 프로토콜 스택에서 최상위 계층이다.
- HTTP에서 보안 기능을 더한 HTTPS는 TLS 혹은 SSL이라 불리기도 하며 HTTP와 TCP사이에 있는 암호화 계층이다.
- HTTP가 메시지를 전송할 경우 현재 연결되어 있는 TCP커넥션을 통해 데이터의 내용을 순서대로 보낸다.
- TCP는 세그먼트라는 단위로 데이터 스트림을 나누고, 세그먼트를 IP패킷에 담아 인터넷을 통해 데이터를 전달한다.
TCP 커넥션 유지하기
컴퓨터는 항상 TCP 커넥션을 여러 개 가지고 있다. TCP는 포트 번호를 통해서 이런 여러 개의 커넥션을 유지한다.
- TCP 커넥션은 4가지 값으로 식별한다. <발신지 IP주소, 발신지 포트, 수신지 IP주소, 수신지 포트>
- 서로다른 두 개의 TCP커넥션은 네가지 주소 구성요소의 값이 모두 같을 수 없다.
TCP 소켓 프로그래밍
- 운영체제는 TCP 커넥션의 생성과 관련된 여러 기능을 제공한다.
- 소켓 API의 다양한 구현체들 덕분에 대부분의 운영체제와 프로그램 언어에서 이를 사용할 수 있게 되었다.
- 소켓 API를 사용하면 TCP종단 데이터 구조를 생성하고, 원격 서버의 TCP종단에 그 종단 데이터 구조를 연결하여 데이터 스트림을 읽고 쓸 수 있다.
#2. HTTP 트랜잭션 지연

클라이언트나 서버가 너무 많은 데이터를 내려받거나 복잡하고 동적인 자원들을 실행하지 않는 한, 대부분의 HTTP 지연은 TCP 네트워크 지연 때문에 발생한다. HTTP 트랜잭션을 지연시키는 원인은 여러 가지가 있다.
- 클라이언트는 URI에서 웹 서버의 IP 주소와 포트 번호를 알아내야 한다. (호스트 방문 내역이 없다면 더 오래 걸림)
- 클라이언트는 TCP 커넥션 요청을 서버에 보내고 서버가 커넥션 허가 응답을 회신하기를 기다린다.
- 커넥션이 맺어지면 클라이언트는 요청을 새로 생성된 TCP파이프를 통해 전송한다. (요청 메시지 전달 및 서버 처리)
- 웹 서버가 HTTP 응답을 보내는 것 역시 시간이 소요된다.
#3. HTTP 커넥션 관리
커넥션 관리가 제대로 이루어지지 않으면 TCP 성능이 매우 안 좋아질 수 있다. 순차적인 처리로 인한 지연에는 물리적 지연뿐 아니라 심리적인 지연도 있다. 특정 브라우저의 경우 객체를 화면에 배치하려면 객체의 크기를 알아야 하기 때문에 모든 객체를 내려받기 전까지 텅 빈 화면을 보여준다. 브라우저는 객체들을 연속해서 하나씩 내려받는 것이 효율적이나 사용자는 진행 상황을 모른채 텅 빈 화면만 보는 불편함을 느끼게 된다.
HTTP 커넥션의 성능을 향상 시킬 수 있는 최신 기술
1. 병렬 커넥션
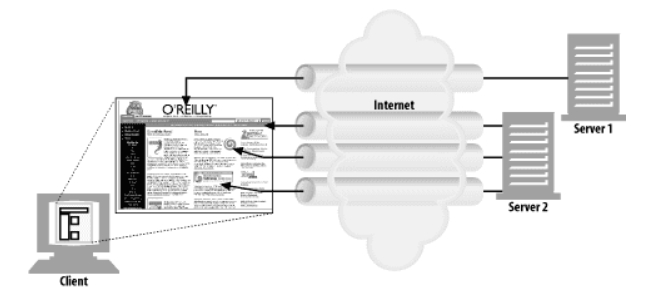
HTTP는 클라이언트가 여러 개의 커넥션을 맺음으로써 여러 개의 HTTP 트랜잭션을 병렬로 처리할 수 있게 한다.
- 각 커넥션의 지연 시간을 겹치게 하면 총 지연 시간을 줄일 수 있고, 클라이언트의 인터넷 대역폭을 한 개의 커넥션이 다 써버리는 것이 아니라면 나머지 객체를 내려받는 데에 남은 대역폭을 사용할 수 있다.
- 병렬 커넥션이 항상 빠르지는 않다. 클라이언트의 네트워크 대역폭이 좁을 때는 대부분 시간을 데이터를 전송하는데만 쓸 것이고, 다수의 커넥션은 메모리를 많이 소모하고 자체적인 문제를 발생시킨다.
- 병렬 커넥션은 페이지를 항상 더 빠르게 로드하지는 않는다. 실제로 페이지의 총 다운로드 시간이 더 걸린다하더라도 , 사용자 입장에서는 화면에 여러 작업이 일어나는 것을 눈으로 확인 하기에 더 빠르다고 여긴다.
2. 지속 커넥션
HTTP/1.1을 지원하는 기기는 사이트 지역성(site locality)를 이용해 처리가 완료된 후에도 TCP 커넥션을 유지하여 앞으로 있을 HTTP 요청에 재사용할 수 있다. 처리가 완료된 후에도 계속 연결된 상태로 있는 TCP 커넥션을 지속 커넥션이라고 한다. ( HTTP/1.0+ 'keep-alive' 커넥션, HTTP/1.1 '지속' 커넥션)
- 지속 커넥션은 병렬 커넥션에 비해 몇 가지 장점이 있다. 커넥션을 맺기 위한 사전 작업과 지연을 줄여주고, 튜닝된 커넥션을 유지하며, 커넥션의 수를 줄여준다.
- 지속 커넥션을 잘못 관리할 경우, 계속 연결된 상태로 있는 수많은 커넥션이 쌓이게 된다. 이는 로컬의 리소스, 원격 클라이언트와 서버의 리소스에 불필요한 소모를 발생시킨다.
- 지속 커넥션은 병렬 커넥션과 함께 사용될 때에 가장 효과적이고, 오늘날 많은 웹 애플리케이션은 적은 수의 병렬 커넥션만 맺고 그것을 유지한다.
3. 파이프라인 커넥션

HTTP/1.1은 지속 커넥션을 통해서 요청을 파이프라이닝할 수 있다. 이는 대기 시간이 긴 네트워크 상황에서 네트워크상의 왕복으로 인한 시간을 줄여서 성능을 높여준다.
파이프라인 제약 사항
- HTTP 클라이언트는 커넥션이 지속 커넥션인지 확인하기 전까지는 파이프라인을 이어서는 안 된다.
- HTTP 응답은 요청 순서와 같게 와야 한다.
- HTTP 클라이언트는 커넥션이 끊어지더라도 완료되지 않은 요청이 파이프라인에 있으면 언제든 다시 요청을 보낼 준비가 되어 있어야 한다.
- HTTP 클라이언트는 POST 요청같이 반복해서 보낼 경우 문제가 생기는 요청은 파이프라인을 통해 보내면 안 된다.
#4. 커넥션 끊기
마음대로 커넥션 끊기
- 커넥션 관리, 특히 언제 커넥션을 끊는가에 대한 명확한 기준은 없다.
- HTTP 클라이언트, 서버, 프락시는 언제든지 TCP 전송 커넥션을 끊을 수 있다. 에러가 없다라도 끊을 수 있다.
- 한 번 혹은 여러 번 실행됐는지에 상관없이 같은 결과를 반환한다면 그 트랜잭션은 멱등하다고 한다. GET, HEAD, PUT, DELETE, TRACE 그리고 OPTION 메서드들은 멱등하다고 이해하면 된다.
- 클라이언트는 POST와 같이 멱등이 아닌 요청은 파이프라인을 통해 요청하면 안된다.
우아하게 커넥션 끊기
- TCP 입력 채널과 출력 채널 중 한 개만 끊거나 둘 다 끊을 수 있다. close()는 모두 끊기, shutdown()은 절반 끊기
- 각기 다른 HTTP 클라이언트, 서버와 통신할 때, 파이프라인, 지속 커넥션을 사용할 때는 절반 끊기를 사용한다.
- 보통은 커넥션의 출력 채널을 끊는 것이 안전하다. 클라이언트가 더는 데이터를 보내지 않을 것임을 확신할 수 없는 이상 커넥션의 입력 채널을 끊는 것은 위험하다.
- 이미 끊기 입력 채널에 데이터를 전송하면 TCP 커넥션 리셋에러가 발생하여 버퍼에 저장된 데이터를 모두 삭제
참조 자료
- HTTP완벽가이드 , 인사이트

'HTTP' 카테고리의 다른 글
| [HTTP] 캐시(Cache) (0) | 2020.05.03 |
|---|---|
| [HTTP] 프락시(Proxy) (0) | 2020.05.02 |
| [HTTP] 웹 서버 (0) | 2020.05.02 |
| [HTTP] HTTP메시지 (0) | 2020.04.30 |
| [HTTP] URL과 리소스 (0) | 2020.04.30 |



